
Data Lake at Robinhood

Data Lake at Robinhood
At Robinhood, we ingest and process terabytes of data every day. This data ranges from real-time streams of market data and in-app events to large files that are essential to our clearing operations. To deliver the best possible experience to customers as we grow, we’ve invested in scaling our data architecture. After evaluating multiple approaches, we designed a data lake system that can support petabytes of data and offer a unified query layer to employees, while ensuring safe and secure data access. In this post, we detail the journey from identifying the challenges that led to the inception of the data lake at Robinhood, to how it was deployed and is currently helping Robinhood scale its data platform efficiently.
Motivation
Working with various data types means there are often different solutions for storing data. We use PostgreSQL and AWS Aurora as our relational databases, Elasticsearch as a document storage and indexing solution, AWS S3 for object storage, and InfluxDB as a time series database. Depending on product needs, we maintain several clusters of each of these systems. As a result, internal users often had to join data across multiple data stores, some of which might have even used different query languages.
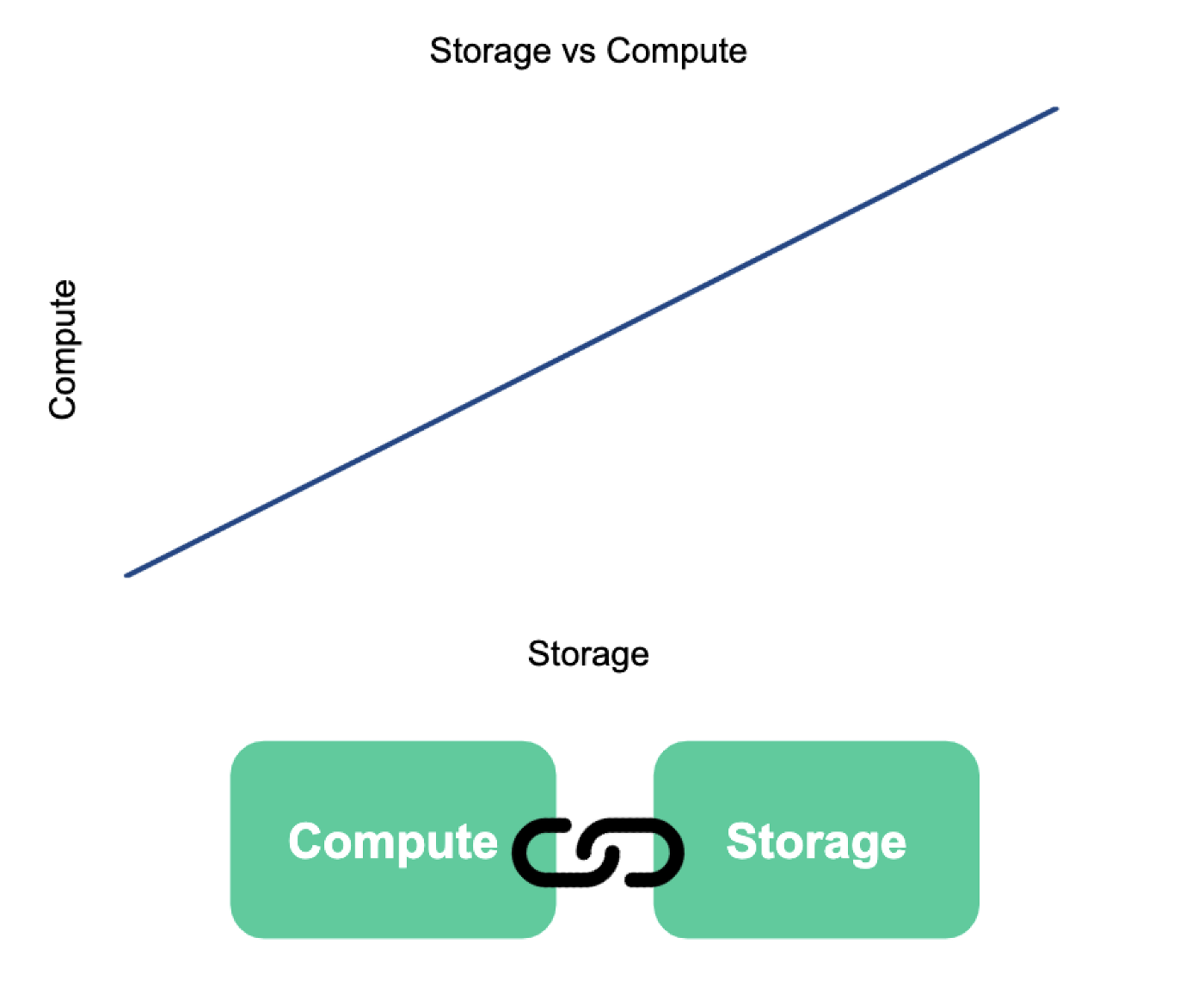
We initially used Elasticsearch and Redshift as our analytics and data warehousing solutions. After a couple of years of maintaining these systems, we determined that scaling these systems to support our increasing data workload was neither efficient nor economical. With storage and compute coupled together on these systems, we would need to scale up our cluster to allow for ingesting more data or adding more jobs on the existing data.
To improve the process of joining data across multiple data stores, we had set up a Jupyter server which had access to multiple data stores. However, these environments lacked a strong identity management system, which made it harder to maintain different levels of access and achieve query-level isolation across different user groups of the research environment.
We wanted to build a solution that would solve all of these problems, and provide us a future-proof and extensible framework as we undergo rapid growth.
Creating Robinhood’s Data Lake
Homework
We researched several potential solutions that would address the unique challenges we face at Robinhood. We read about how Netflix and Uber leveraged Presto and Parquet to scale their data platforms, and how other financial institutions like FICO and National Bank of Canada leveraged big data tools on the cloud. We also looked into the criticism and failure cases for data lakes.
With this insight, we developed an initial architecture for a data lake on the cloud leveraging managed solutions. It was important that the solution we opted for could be set up with minimal effort and operational overhead.
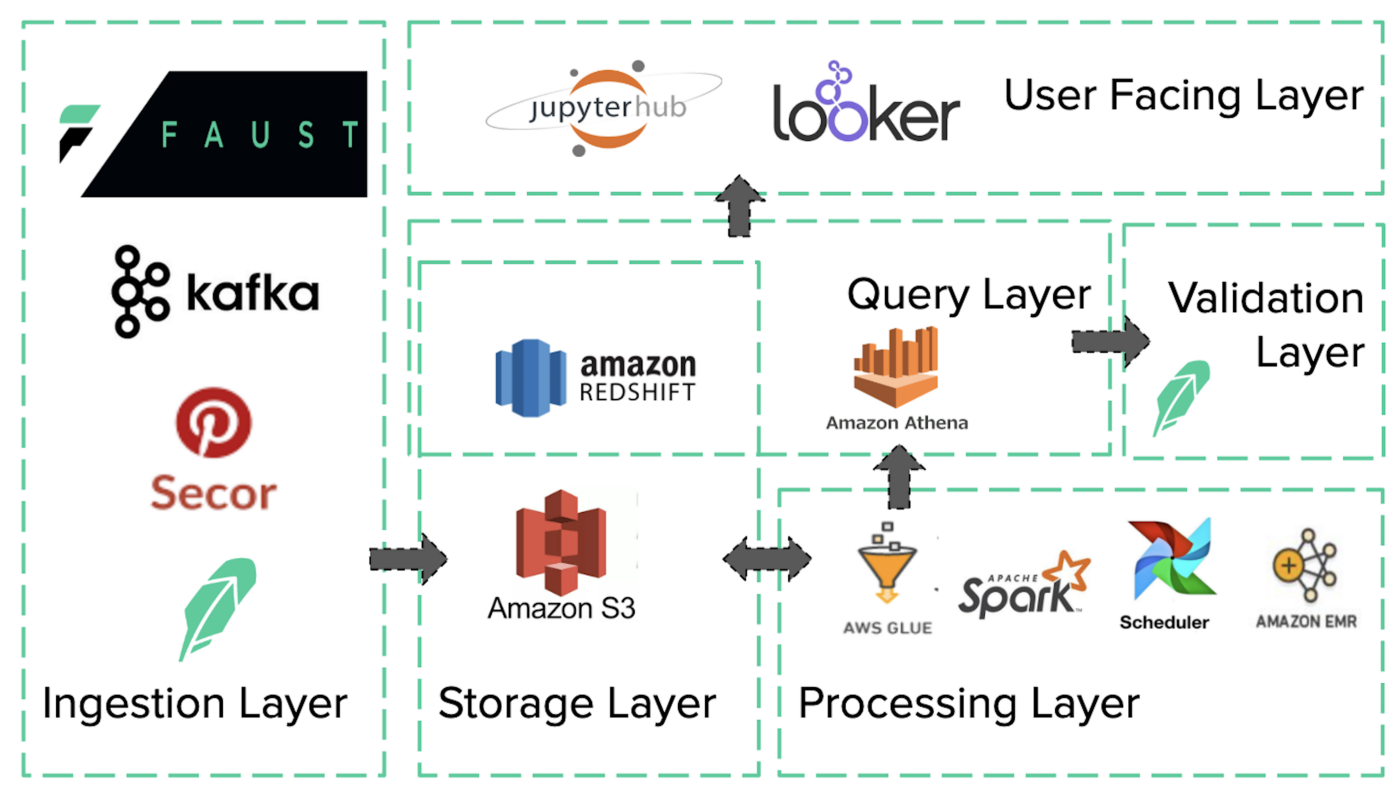
Ingestion
Data enters the systems at the ingestion layer in two forms: stream or batch. We use Kafka as our databus to stream data, which usually comes from external feeds, or from internal Faust apps. We use Secor to archive our Kafka streams to S3 and for batch data, we have internal systems directly post the data to S3.
Storage
Our goal for the storage layer was to provide cost-efficient, performant and reliable storage. We primarily use S3 for this layer since it provided all of these functionalities and abstracted away all the complexities of managing a distributed file storage system. We use Redshift in a more focused role for storing derived datasets that power some frequently used dashboards in our business intelligence tool. We also backup the source data stores in AWS Glacier for longer durations as a cold storage.
Processing
Some of our datasets, like in-app events or load balancer logs, are too big to query efficiently in its raw form, and most of the data is likely irrelevant to any particular query. Therefore, we process these datasets further to split them up into mini-sets and calculate aggregate metrics using distributed data processing tools like Spark. To avoid the overhead of managing our own cluster, we use AWS Glue, which offers a serverless Spark framework. After processing these datasets, we post the results back to S3 in Parquet columnar format using Snappy compression. To automatically generate the schemas for these datasets and make these datasets discoverable using a metastore, we use Glue crawlers and the Glue metastore, respectively. We use Airflow to orchestrate the process, which usually involves these steps:
- Run a crawler to detect the schema (usually only for new datasets)
- Add new partitions for the raw data to the metastore
- Run a processing job
- Add new partitions for the processed data to the metastore
Querying
After we developed a solution to process our data, we needed to setup some tooling to allow employees to query this data. We primarily use Presto, and in order to get up and running without having to set up our own Presto cluster, we enlisted AWS Athena, a managed Presto solution. Athena works seamlessly with the Glue metastore to discover the processed data stored in S3. In addition to Presto, a subset of our queries from the visualization layer also go to the Redshift cluster that stores some aggregated datasets.
Validation
Most data lake failure cases discussed a disconnect between producers and consumers of the data. If producers post arbitrary data with no checks and balances into the data lake, consumers tend to lose faith in the quality of data, turning the system into a data graveyard. We tried to proactively tackle this issue by creating a data validation framework and enforcing a producer-driven validation model. The framework very simply allows the owner of the dataset to specify some common-sense thresholds about their data, like the expected number of rows, uniqueness constraints, or categorical values. Once the data is processed, we run a verification task that runs queries using Athena or Redshift and verifies that all the preset tests pass before making the data available to users.
User Interaction
Employees that need to interact with the data in the lake can do so in a couple of different ways. We use Looker as our business intelligence and data visualization tool at Robinhood. For more complex data use cases, we provide a Jupyter notebook research environment based on top of Jupyterhub. This system is usually used by data scientists and engineers for exploratory data analysis, and training and testing machine learning models.
Current State
After building the initial tooling, we spent quite a bit of time training users, writing documentation and customizing our internal tools to work with the data lake. Robinhood’s data lake was quickly adopted within the company since it was built to meet the needs of internal users and quickly delivered value.
Here is a snapshot of where we are today with our Data Lake:
We’re continuing to make the onboarding process as easy as possible for technical and non-technical users alike.
Looking Ahead
Data lake has had a positive impact on our internal teams, so we’re investing in strengthening different pieces of this system.
To gain more fine grained tuning controls and visibility into our Spark jobs, we set up a couple of self-managed Spark clusters with around 50 nodes each. Similarly, we brought up a 50-node Presto cluster to work past some of the limitations we noticed with Athena.
A few improvements in the works are:
- Migrating our bigger workflows from Glue to our in-house Spark cluster.
- Migrating from Athena to our in-house Presto cluster for all our interactive query needs.
- Moving our research notebook system from a single monolithic instance to a distributed environment like Kubernetes, with something like Kubespawner. This would allow different workflows to be isolated and make it easier to roll out upgrades for the system.
We’ve created a simple, yet strong, foundation to build out most of these complex functionalities. If you’re as excited as we are about solving these types of challenges, we encourage you to come join us on the Data Platform team at Robinhood.
If you’re interested in learning more, we talked about our journey of building the data lake and our use of AWS Glue at AWS re:Invent 2018.


