
From News to Newsfeed

In October, we announced the launch of our fully rebuilt newsfeed. We added content from Barron’s, Reuters, and The Wall Street Journal, as well as videos from CNN Business, Cheddar, and Reuters. In November last year, we talked about how we improved our News system. Since then, we have invested in the system architecture to support our rebuilt newsfeed that delivers even richer content and continues to keep you informed in a timely manner. In this post, we will provide a high level explanation of the overall revamped system.
Robinhood’s Newsfeed
In our previous discussion, we mentioned that we use Faust to achieve a system that can serve news retrieved from RSS feeds to customers within a few minutes. To provide customers with even more trusted news sources, we identified news publishers that we could partner with to bring their content into the Robinhood app. During our initial discussion with our partners, we realized that there were areas of our existing system that would need to be re-designed to support providing the in-app news experience we envision for our customers. This includes what we’re delivering today, but also future improvements we believe we can make to provide an even more personalized Robinhood experience.
Therefore, we went back to the drawing board to design a system that can offer the following technical requirements:
- Timely delivery of news from our partners and RSS feeds to customers (this includes content ingestion, storage and delivery to our customers).
- Scalable content ingestion pipeline and storage to accommodate various content types: videos and news articles.
- Infrastructure to support opportunities to personalize content served.
We adopted a microservice architecture to build our newsfeed system. We modularize our systems into the following services:
Content Aggregation
This layer is a collection of microservices that is responsible for aggregating and storing content from partners and RSS feeds. We use Faust agents to extract links from RSS feeds, parse the links to get the content, and process the content to ensure they are correctly tagged. Faust allowed us to stream large amounts of content in a distributed manner easily. The number of agents can be adjusted to meet the volume of incoming content.

Between each process, we use Kafka as a buffer. Even though we have a buffer, it is important to ensure that each process has a strict timeout for each piece of content. Otherwise, an errant HTTP request to fetch content can cause delays in the pipeline that result in less timely news for our customers.
For content providers that do not provide RSS feeds, they usually have a partner-specific feed or API that we can query to retrieve content. In these cases, the parse step can be skipped since they return the content along in the feed or API calls.

We chose Elasticsearch as the storage system for the text content that we get from our partners as it is known for its rich text features based on Lucene. It is highly scalable as we can increase the number of nodes to store more content, and replicas to handle more traffic.
Feed Ranking
Our next layer of microservices is the feed ranking layer. This layer is composed of services connected to a user feature store and a S3 storage bucket containing machine learning models for personalization efforts of the newsfeed.
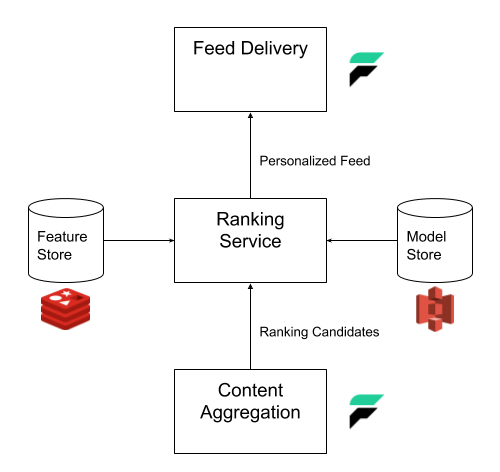
The feature store contains pre-generated data to provide ranking signals for our models. Our data scientists work with our engineers to update the models and feature store on a regular basis. Currently, the models tailor the newsfeed based on customers’ positions and watchlists, but we believe there’s a lot more we can do to make newsfeed even more personalized. We decided on using Redis as our feature store as we find the Redis cluster being able to support very fast lookup of user features. The cluster could also easily scale with the number of customers.
Feed Delivery
After generating the newsfeed, we need to provide APIs for the Robinhood app that our customers use to interact with our newsfeed. Besides retrieving the newsfeed, customers may also post feedback or request for a specific content type. To facilitate these interactions in a scalable manner, we used Faust server capabilities to handle the incoming and outgoing network traffic. Faust server is built using Python asynchronous framework and hence it allows us to serve more traffic with less server instances. We also added a caching layer for our Faust server to reduce the workload on our ranking service for requests that occur very close to each other.
One major learning that we have from designing this layer is to ensure that we work very closely with our frontend engineers to agree on an API specification for the newsfeed. We created a specification that explicitly indicates how the content should be displayed and what the content is. Here is an example of how we design one of the items in the API response representing a newsfeed element to be displayed.
{ 'id': '1234–1234–1234–1234', 'templates': ['news_hero'], 'contents': [{…}], …}
The templates field is a list of template names that the Robinhood app will use to render contents into. These templates are preloaded on the frontend apps. The value of the field is a list of template names because we provide multiple templates for the content to support backward compatibility. This separation of display and content into two different fields gives us the flexibility to run backend driven experiments. We can vary the templates to change how the content appears to our customers or adjust the mix of videos to news articles without any frontend changes. However it is important to know that it is the responsibility of the backend systems to ensure that the contents can be rendered into one of the templates otherwise the Robinhood app is programmed to omit the content.
The three layers that we described above work together to enable us to keep you updated with comprehensive finance news from trusted news sources and ad-free video wherever you are. Whenever the newsfeed loads in the Robinhood app for our customers, the layers interact in the following ways:
- At the content aggregation layer, all relevant content for the customer is gathered and sent to the feed ranking layer.
- The feed ranking layer orders the content based on any preloaded models for the customer.
- The feed delivery layer serves the ordered content as a JSON response to the customer’s Robinhood app and it is rendered as the newsfeed.
In future blog posts, we will share more details about how we built each layer and lessons we learned in the process. Many thanks to Charles Chen, Sanyam Satia, Jin Gong, Joseph Song, Michelle Lim, Arpan Shah, and Shanthi Shanmugam for their contributions towards this effort!
If you’re interested in working on similar projects as we work to democratize our financial system, join our data team! We’re hiring!


