Goaway Chance – Chronicles of Client Connection Lost

Robinhood was founded on a simple idea: that our financial markets should be accessible to all. With customers at the heart of our decisions, Robinhood is lowering barriers and providing greater access to financial information and investing. Together, we are building products and services that help create a financial system everyone can participate in.
…
Authored by: Eric Ngo
Edited by: Nick Turner and Sujith Katakam
Distributed systems are complex. Even more so are their interactions with one another. One such system that exemplifies this is none other than Kubernetes, whose adoption has been increasing rapidly. As we introduce more components (and thus complexity) into our clusters, the job of understanding the downstream impact of changes becomes harder. On the Software Platform team here at Robinhood, we as Kubernetes practitioners have to go into great depths to debug issues in our systems that stem from the smallest of configuration changes. In this blog post, we will go over a recent example in which we dove deep into kernel settings, NLB configurations, and open source code to root cause connectivity issues caused by setting an innocuous Kubernetes API Server setting.
The Problem:
Kubernetes clients using client-go are configured to use http2 when connecting with the API server. http2 leverages persistent TCP connections and the idea of streams to multiplex multiple HTTP requests onto a single TCP connection. As a result, http2 achieves better performance by reducing RTT by avoiding having to re-establish new TCP & TLS handshakes on each request compared to HTTP 1.1. We observed a pattern, where, due to those long running persistent connections, the load on our API servers became imbalanced. This results in disproportionate load on the API servers and can have a cascading effect on the reliability of the system. This imbalance often happens when we perform rolling updates of our control plane nodes, a common operation when updating or making configuration changes to our control plane components.
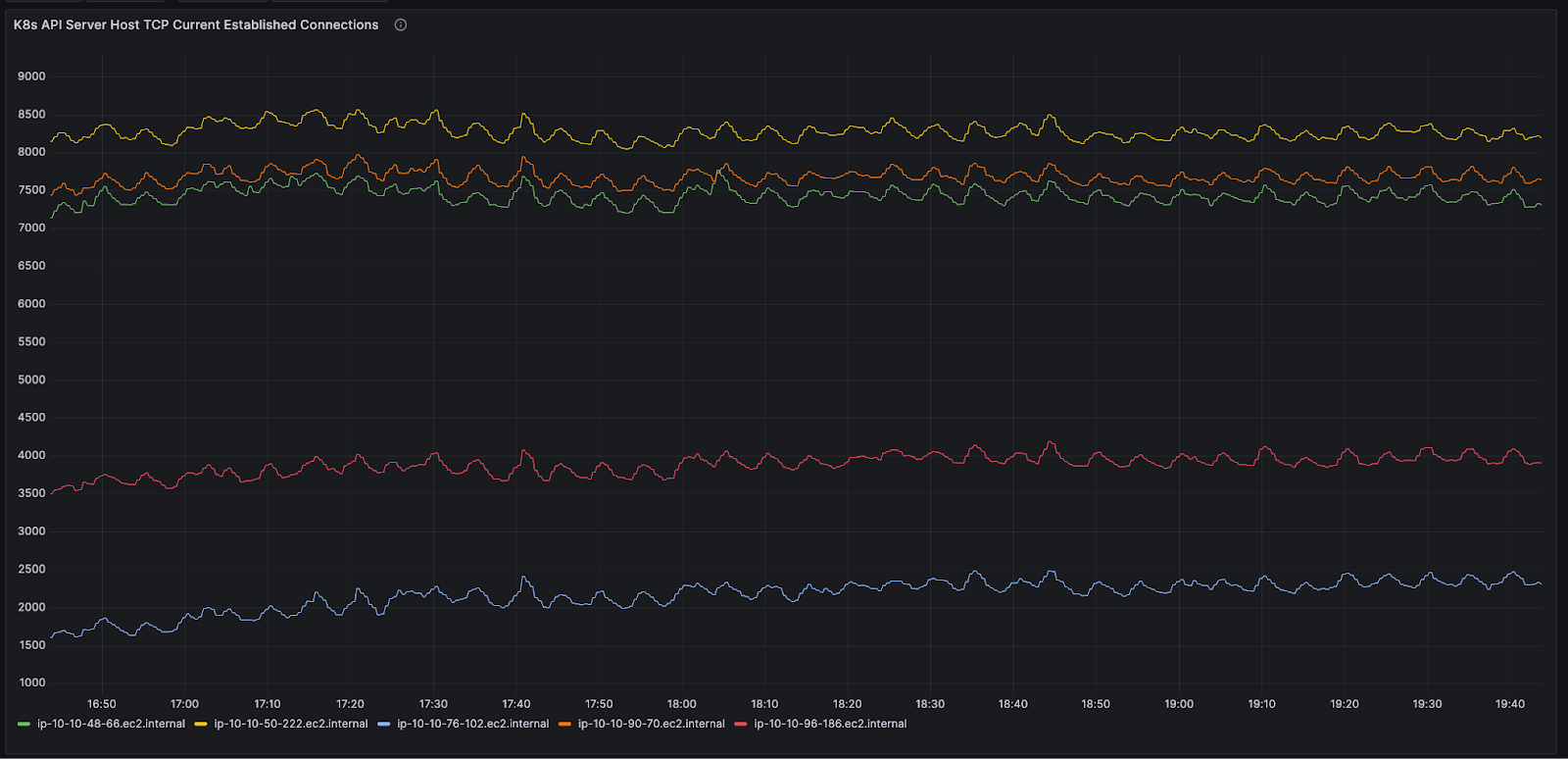
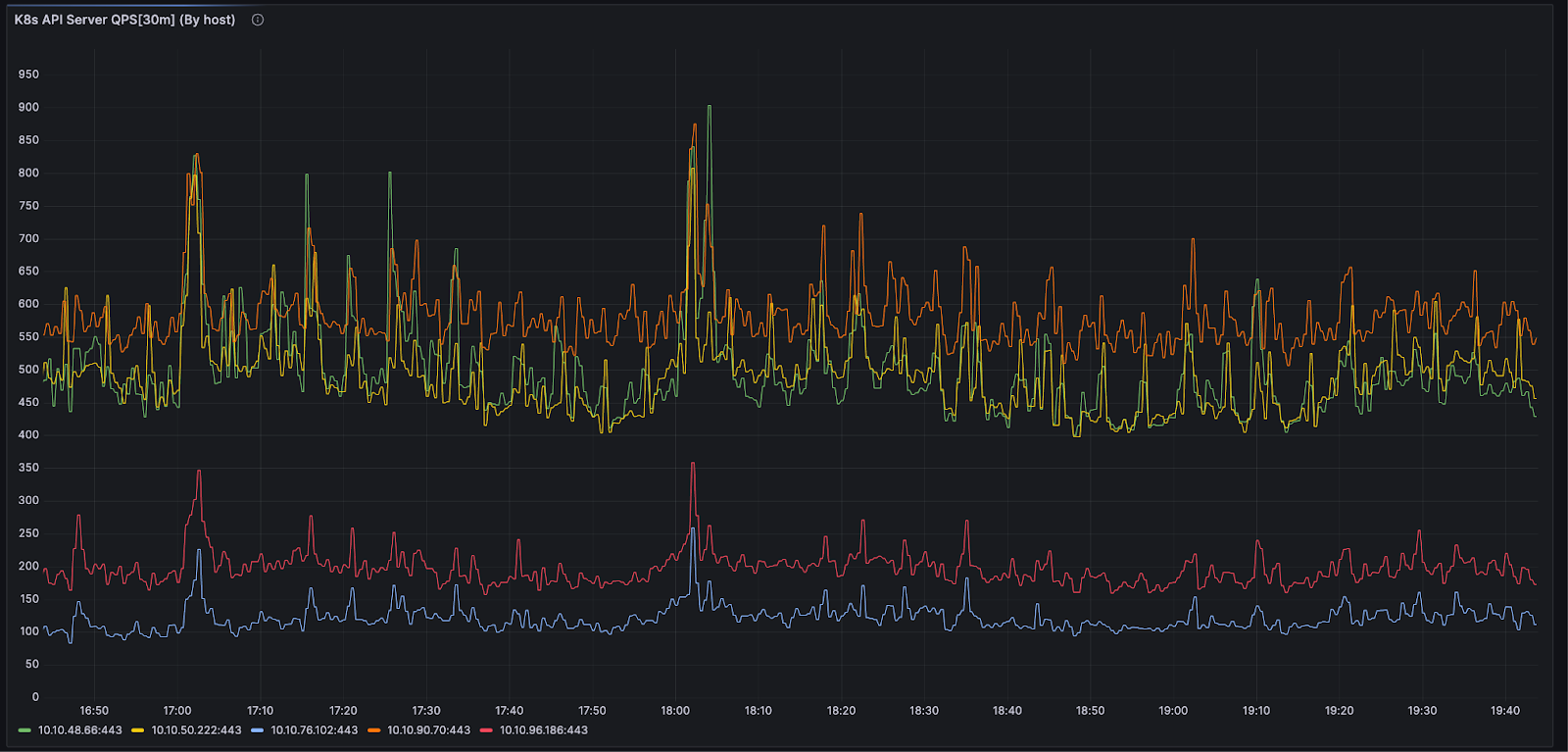
To get around the issue of client stickiness, we decided to configure the Kubernetes API server flag –goaway-chance. Introduced in k8s 1.18(ref), –goaway-chance is an API server HTTP filter which probabilistically sends an RST_STREAM to http2 clients, forcing clients to create new requests on newly reestablished TCP connections. By enabling this setting, we were able to achieve significantly improved connection balancing and load distribution.
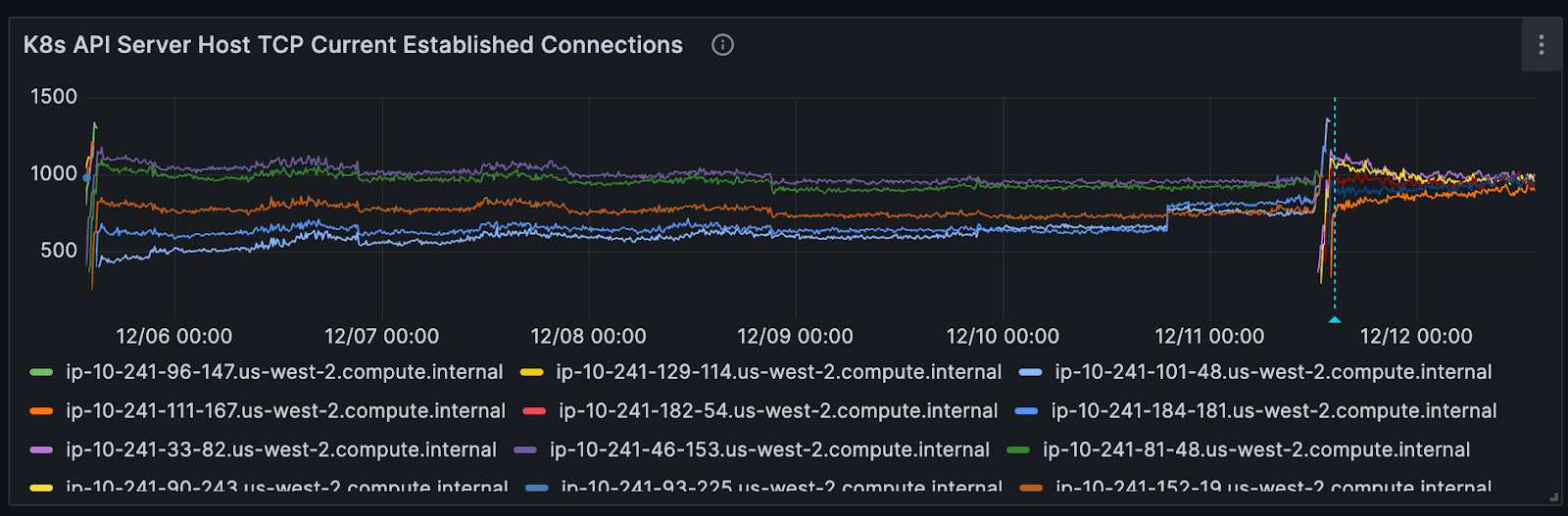
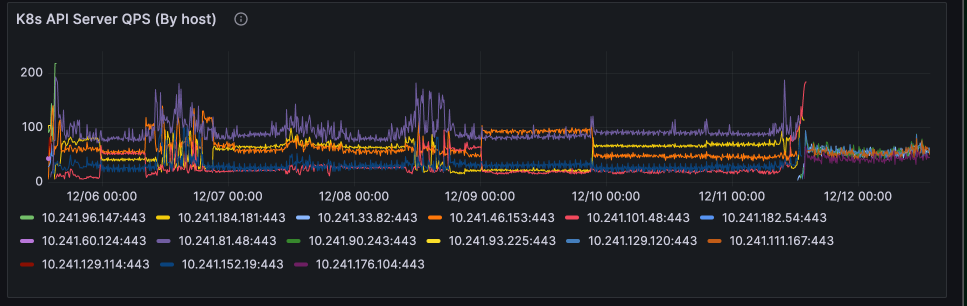
Post the rollout of –goaway-chance to our pre production environments, we began to notice symptoms such as Nodes marked as NotReady happening occasionally in our clusters.
node ip-10-241-33-82.us-west-2.compute.internal hasn't been updated for 40.956376745s. Last Ready is: ...On further inspection, we noticed that kube-controller-manager was marking nodes as not ready. Kubelets on each node are in charge of updating the node’s kube-node-lease, which acts as a heartbeat mechanism for whether or not the Node is able to communicate with the API server. The kube-controller-manager runs a control loop called “node_lifecycle_controller”, in charge of updating the Ready status condition of nodes if nodes have renewed their kube-node-lease in time. By default, kubelet updates Lease objects every renewInterval of 10 seconds, and kube-controller-manager checks if the Leases have been renewed within nodeMonitorGracePeriod of 40 seconds. Thus upon receiving a handful of nodes reporting as NotReady, this could mean one of two things: a handful of nodes actually are unhealthy (kubelets unable to perform heartbeats) or kube-controller-manager’s lease informer is not receiving updates.
Upon checking the kubelet logs and audit logs of heartbeat updates for a node marked as not ready, we quickly ruled out kubelet as the cause. Thus we focused our attention on kube-controller-manager and found a rather curious log line:
W1215 09:45:02.898142 1 reflector.go:441] k8s.io/client-go/informers/factory.go:134: watch of *v1.Lease ended with: an error on the server ("unable to decode an event from the watch stream: http2: client connection lost") has prevented the request from succeedingWhat is client connection lost and how does this relate to the informer not receiving any updates for 40+ seconds?
Client Connection Lost
Remember that HTTP2 utilizes persistent TCP connections. Because it is the internet, any handful of things can happen between the client and the server. Thus http2 allows health checking to be able to detect when there are issues on the remote end. In the Kubernetes golang client library (k8s.io/client-go), these health checks are performed by the net/http2 library in the form of http2 pings.
// closes the client connection immediately. In-flight requests are interrupted.
func (cc *ClientConn) closeForLostPing() {
err := errors.New("http2: client connection lost")
if f := cc.t.CountError; f != nil {
f("conn_close_lost_ping")
}
cc.closeForError(err)
}These pings are performed after “ReadIdleTimeout” seconds of not receiving any frames on the connection. After “PingTimeout” seconds, the connection will be closed.
// ReadIdleTimeout is the timeout after which a health check using ping
// frame will be carried out if no frame is received on the connection.
// Note that a ping response will is considered a received frame, so if
// there is no other traffic on the connection, the health check will
// be performed every ReadIdleTimeout interval.
// If zero, no health check is performed.
ReadIdleTimeout time.Duration
// PingTimeout is the timeout after which the connection will be closed
// if a response to Ping is not received.
// Defaults to 15s.
PingTimeout time.DurationKubernetes default transport configures the ReadIdleTimeout and PingTimeout to be 30 seconds and 15 seconds respectively.
func readIdleTimeoutSeconds() int {
ret := 30
// User can set the readIdleTimeout to 0 to disable the HTTP/2
// connection health check.
if s := os.Getenv("HTTP2_READ_IDLE_TIMEOUT_SECONDS"); len(s) > 0 {
i, err := strconv.Atoi(s)
if err != nil {
klog.Warningf("Illegal HTTP2_READ_IDLE_TIMEOUT_SECONDS(%q): %v."+
" Default value %d is used", s, err, ret)
return ret
}
ret = i
}
return ret
}
func pingTimeoutSeconds() int {
ret := 15
if s := os.Getenv("HTTP2_PING_TIMEOUT_SECONDS"); len(s) > 0 {
i, err := strconv.Atoi(s)
if err != nil {
klog.Warningf("Illegal HTTP2_PING_TIMEOUT_SECONDS(%q): %v."+
" Default value %d is used", s, err, ret)
return ret
}
ret = i
}
return ret
}The readIdleTimeout and pingTimeout sums up to 45 seconds, which could explain why the lease informer receives no updates for more than 40 seconds, thereby causing kube-controller-manager to assume that the nodes have expired passed their 40 second leaseDuration, and causing nodes to be marked NotReady. But a question remains: why did the connection hang for 45 seconds?
Our Setup
NLB
For each of our clusters, an NLB balances connections to our API Servers. These NLBs are configured with client-ip preservation and cross zone load balancing enabled. Client IP preservation was enabled to allow the number of concurrent connections going through the NLB to exceed the NLB’s ephemeral port range of 65000. Cross zone load balancing was enabled to improve reliability and resiliency to partial control plane outages.
API Server and Kube Controller Manager
We bootstrap our clusters using kOps, a kubernetes cluster management tool. Each cluster has 5 control plane nodes. All control plane components such as kube-controller-manager, kube-scheduler, etc., sit on the control plane nodes and are configured to talk to the API servers through the NLB.
Nodes
Our nodes are configured with net.ipv4.tcp_tw_reuse = 1, which permits sockets in TIME_WAIT state to be reused, as well as for ports configured to different targets to be reused as well. An unbound port can be reused as long as the 5-tuple (protocol, source ip, source port, destination ip, destination port) for the connection is different, so that the kernel can differentiate the new connection from the existing connection.
Now that we understand the setup better, let’s go about reproducing the issue.
Reproduction
Vanilla Clusters
Initially believing it to be solely due to goaway-chance, we tried reproducing the bug by creating a vanilla cluster with kube-controller-manager talking directly to the API server through localhost. The network path looks something like the following:
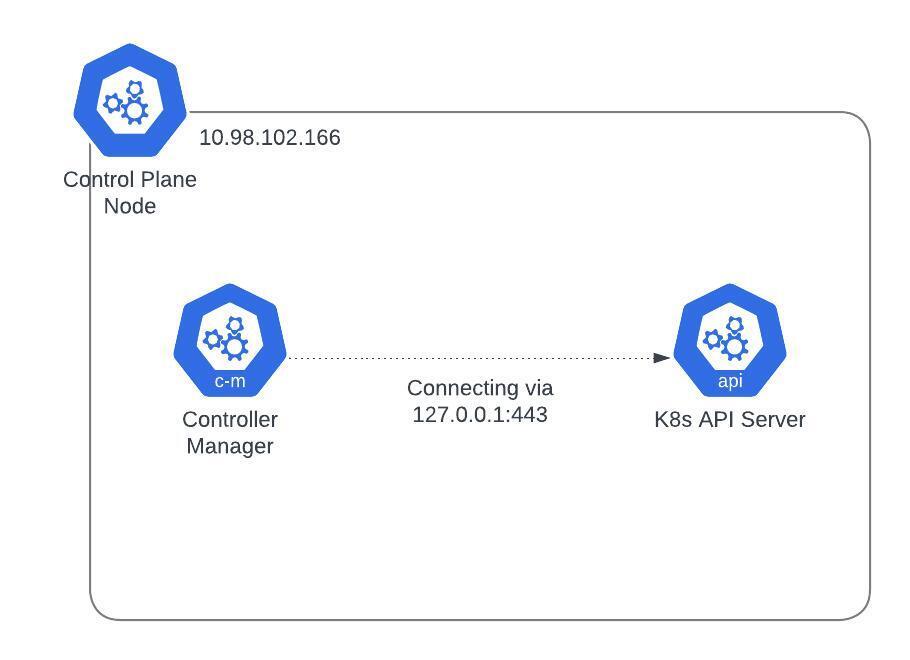
After setting goaway-chance however, we were not able to reproduce the issue. The only difference between the setup of our vanilla cluster and that of our running clusters is the fact that the control plane components route to the API servers through the NLB, thus we decided to add an NLB to our test environment.
Reference
For reference, the IPs referenced below are configured with the following:
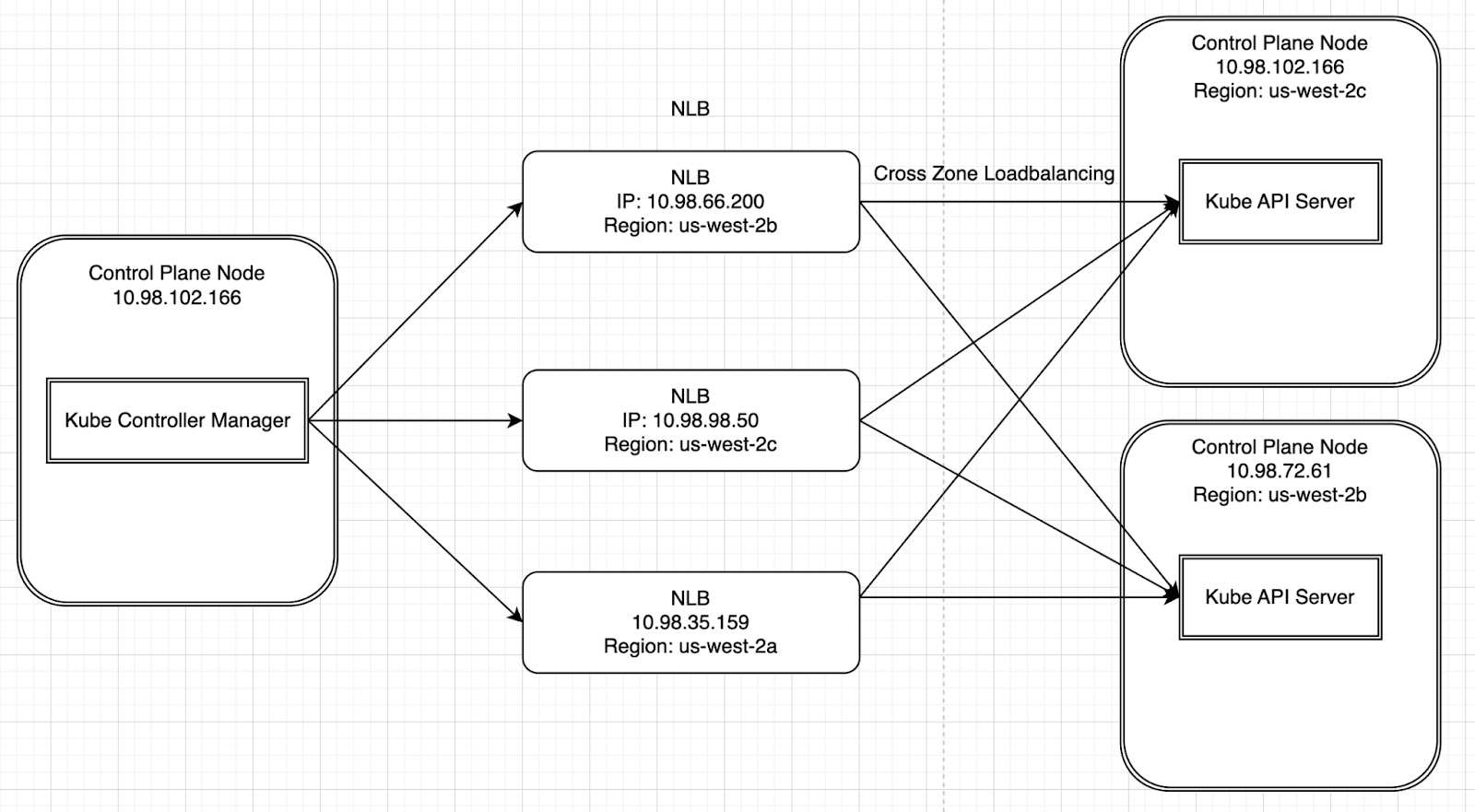
Our NLBs are backed by the following instances in the respective availability zones. Note that because we have cross zone load balancing enabled, each of the NLB instances is able to talk to any of the apiserver targets.
| NLB IP | NLB Zone |
| 10.98.35.159 | us-west-2a |
| 10.98.66.200 | us-west-2b |
| 10.98.98.50 | us-west-2c |
Because we only care about the interaction between kube-controller-manager and kube-apiserver, the instances in question with the running processes are:
| Control Plane Host IP | Running Processes |
| 10.98.102.166 | Kube-controller-manager, kube-apiserver |
| 10.98.72.61 | kube-apiserver |
And for the sake of completeness, here is a diagram of our system:
Going through the NLB
We configured kube-controller-manager to talk to the NLB by setting the `–master` flag and were quickly able to reproduce our “client connection lost” issue. But what did the NLB have to do with the “client connection lost” issue? To better understand what the net/http package is doing under the hood and to understand the state of tcp connections, we will do the following:
- Set GODEBUG=http2debug=2 to enable verbose HTTP/2 logs with frame dumps (ref)
- Configure the kube-controller-manifest’s environment variable to set key: GODEBUG with value: http2debug=2
- Run a packet capture on the client (kube-controller-manager)
- tcpdump -nni any src 10.98.102.166 or dst 10.98.102.166 -w client.pcap
This will allow us to correlate net/http2 activity with tcp dumps so we can pinpoint tcp streams in question and analyze them.
Inspecting http2debug logs
After enabling http2debug logs, we were able to capture the http2 activity during an occurrence of “client connection lost”.
// http2debug logs:
{"log":"I0125 01:56:38.494896 1 log.go:184] http2: Framer 0xc00151c1c0: read DATA stream=5 len=2535 ...
{"log":"I0125 01:56:38.494946 1 log.go:184] http2: Framer 0xc00151c1c0: wrote WINDOW_UPDATE stream=5 len=4 incr=5066\n","stream":"stderr","time":"2024-01-25T01:56:38.494997074Z"}
{"log":"I0125 01:57:08.495926 1 log.go:184] http2: Framer 0xc00151c1c0: wrote PING len=8 ping=\"x\\x85ex\\xc5*\\xd1\\xd5\"\n","stream":"stderr","time":"2024-01-25T01:57:08.495982798Z"}
{"log":"I0125 01:57:23.496850 1 log.go:184] http2: Framer 0xc00151c1c0: wrote RST_STREAM stream=5 len=4 ErrCode=CANCEL\n","stream":"stderr","time":"2024-01-25T01:57:23.496895388Z"}
{"log":"I0125 01:57:23.496896 1 log.go:184] http2: Framer 0xc00151c1c0: wrote RST_STREAM stream=1 len=4 ErrCode=CANCEL\n","stream":"stderr","time":"2024-01-25T01:57:23.496937986Z"}
{"log":"W0125 01:57:23.496885 1 reflector.go:441] k8s.io/client-go/informers/factory.go:134: watch of *v1.Pod ended with: an error on the server (\"unable to decode an event from the watch stream: http2: client connection lost\") has prevented the request from succeeding\n","stream":"stderr","time":"2024-01-25T01:57:23.496924308Z"}At 1:56:38, the framer 0xc00151c1c0, which handles request multiplexing on a single tcp connection, reads some data from the server and performs a WINDOW_UPDATE. The connection does not receive any updates for the readIdleTimeout of 30 seconds, so the library writes a PING to the server. After the pingTimeout of 15 seconds, the client eventually writes an RST_STREAM to terminate the stream, and logs “client connection lost”. To pinpoint and analyze the affected tcp streams, we will align the activity above with tcp dumps.
Kube-controller-manager TCP Dump
Analyzing 10.98.102.166:42852 <> 10.98.66.200:443
Having taken a packet capture during an occurrence of client connection lost, we found a near identical tcp stream (tcp.stream eq 1110) that aligns with the http2 debug logs. We see that the KCM host 10.98.102.166 is talking to one of the NLBs 10.98.66.200.

We see a frame received at 15:56:38, 30 seconds later the client 10.98.102.166 sends a PING at 15:57:08. There seems to be a response but upon inspection of the packet, the acknowledgement number of frame 138783 does not match the Sequence number of the frame 138772. After the pingTimeout of 15 seconds at 15:57:23, we see the client sends an RST_STREAM followed by the closing of the connection.
Let’s analyze the rest of the stream to see if we see anything suspicious.

Interesting! There is a tcp port number reused warning. Could there be other streams using the same port?
Analyzing 10.98.102.166:42852 <> 10.98.98.50:443

We see another tcp stream whereby the client 10.98.102.166 is talking to a separate NLB 10.98.98.50 using the same port as earlier from 42852 -> 443. Note our nodes have tcp_tw_reuse = 1, thus ports are allowed to be reused as long as the 5-tuple socket fields (protocol, source ip, source port, client ip, client port) are different. This seems normal, but is there anything anomalous with this stream?

This stream also suffers from the same symptom, where by it last receives data at 15:56:08, sends a PING 30 seconds later at 15:56:38, and after failed attempts to retransmit, eventually sends an RST_STREAM at 15:56:53 and terminates the connection. This stream similarly receives the “client connection lost” errors we have previously seen. Let’s filter for the port in its entirety.
Analyzing the port 42852

Aha! It seems that at the time in which the connection from 10.98.102.166:42852<>10.98.98.50:443 was broken, the client attempts to establish a new connection with a different NLB 10.98.66.200 using the same client port. At frame 36711, the client sends a SYN. However, the server responds with a challenge ACK instead of a SYN-ACK due to an existing connection that the server still considers open. The client then sends an TCP RST packet, severing the connection on both ends and completely resetting the connection state on both ends. After which the client 10.98.102.166:42852 is able to successfully perform a TCP handshake with the NLB 10.98.66.200:443.
What’s going on here?
Let’s quickly touch upon the NLB and what it could be doing here. The NLB is a Layer 4 load balancer (TCP/IP layer) that receives connections and acts as a proxy between the client and the server. The NLB that fronts our API servers has a feature called client IP preservation, which we enabled. This feature essentially replaces the source IP & ports of the TCP packets to be that of the sender instead of itself. This lets the targets receive many more connections as well as preserves the IPs for any sort of tracing, auditing, etc.. In addition to client ip preservation, it also has cross zone load balancing enabled, which permits the NLB to route to any of the backend targets.
All this means that from the client side, even if it is routing (using the same port) to different NLB IPs, the NLB routed targets may still route to the same host. From the server side, it sees a new connection attempt on an already established socket and sends a challenge ACK which prompts reset(RST) of the connection.
In this instance, it seems that the client (10.98.102.166), reusing the same port (42852), goes through different NLBs (10.98.98.50:443 & 10.98.66.200:443) but land on the same target (10.98.72.61:443). This could explain why when opening the second connection to 10.98.66.200 using the same port, we receive a challenge ACK, and after sending an RST packet, why the initial connection to 10.98.98.50 gets severed and the new connection to 10.98.66.200 is permitted.
To visualize this better, here is a diagram:
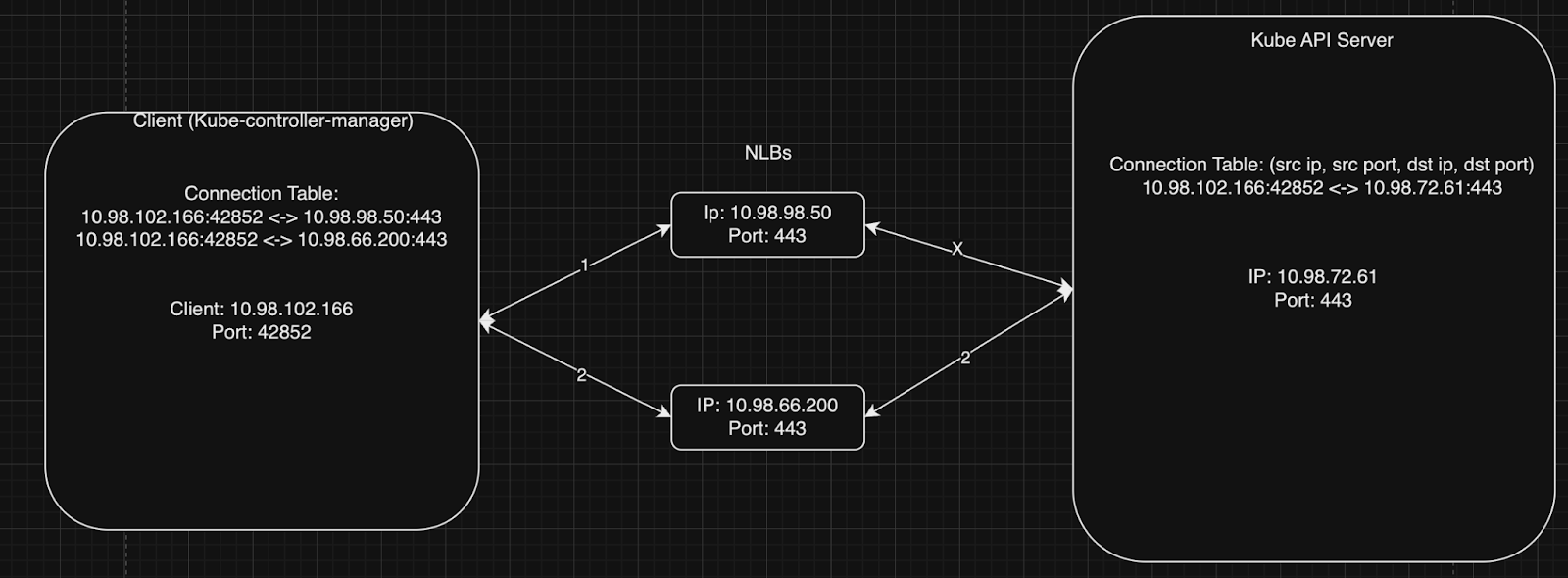
Initially, kube-controller-manager and kube-apiserver’s socket states are empty. Kube-controller-manager first opens a socket connection with the 5-tuple (tcp, 10.98.102.166, 42852, 10.98.98.50, 443). The NLB routes the connection to the API server 10.98.72.61, whose “connection table” now holds the socket state (tcp, 10.98.102.166, 42852, 10.98.72.61, 443). A little while later, upon receiving GOAWAY, the client establishes a new connection reusing the port 42852 and now has the 5-tuple (tcp, 10.98.102.166, 42852, 10.98.66.200, 443). Notice this is the same client IP, and a different NLB IP. The NLB attempts to establish a connection to the same target. Now the kube API server, due to client ip preservation, sees that the connection already exists in the connection table (the client port is the same due to port reuse). Upon receiving a SYN in the middle of an already established connection, it sends a challenge ACK. When the client sends an RST, the server completely resets the connection state for the client ip & port pair 10.98.102.166:42852, completely severing the initial connection, allowing a new connection to be established with the same client port.
For completeness, we did another reproduction and captured the tcpdump on the server side which captures exactly what we have deduced:

The server receives a SYN in the middle of a tcp stream that has an invalid Seq / Ack #. It responds with a challenge ACK, to which the client then responds with an RST which severs the TCP connection on the server side.
In summary, client ip preservation & cross zone load balancing are enabled, tcp_tw_reuse=1 is set on the client, and connections from the same client (src ip, src port), routing to different NLBs, land on the same target (dst ip, dst port). This results in the load balancer targets receiving unexpected SYNs on existing tcp connections to send a challenge ack, to which the clients responds with an RST, severing the connection on the server side. This causes existing long lived HTTP/2 streams (such as informer Watch connections) to receive “client connection lost” after timing out for 45 seconds.
NLB Documentation
But what the heck? Isn’t this an NLB bug? Well, it’s not so much of a bug as it is a feature of NLBs due to client ip preservation & cross zone load balancing. As AWS states in their NLB “Requirements and considerations”:
NAT loopback, also known as hairpinning, is not supported when client IP preservation is enabled. When enabled you might encounter TCP/IP connection limitations related to observed socket reuse on the targets. These connection limitations can occur when a client, or a NAT device in front of the client, uses the same source IP address and source port when connecting to multiple load balancer nodes simultaneously. If the load balancer routes these connections to the same target, the connections appear to the target as if they come from the same source socket, which results in connection errors. If this happens, the clients can retry (if the connection fails) or reconnect (if the connection is interrupted). You can reduce this type of connection error by increasing the number of source ephemeral ports or by increasing the number of targets for the load balancer. You can prevent this type of connection error, by disabling client IP preservation or disabling cross-zone load balancing.The two considerations here are generally:
- Disable client ip preservation at the cost of limiting the number of concurrent connections down to the ephemeral port range of ~65000
- Disable cross zone load balancing, which will prevent different load balancers instances from routing connections to the same backend.
For the sake of –goaway-chance, we decided on setting a value low enough to only induce port reuse less than 1% of the time.
While testing, we also ran into the issue described above with NLB loopback timeout, whereby NLB targets that are a client of themselves may invalidate packets when source IP == destination IP. We are working around this by ignoring specific userAgent in the kube-apiserver’s GOAWAY filter to not have to induce this loopback timeout during reconnection.
Takeways
When working with distributed systems, changes often have unexpected effects. It’s important for those of us who manage these systems to be comfortable with our tooling and unafraid of diving deep into behavior that we don’t understand. These opportunities arise on a regular basis on my team here at Robinhood. If you’re interested in working on Kubernetes and love going deep, consider applying! We’re currently hiring a Senior Software Engineer to join our Container Orchestration team. Learn more and apply here.
Shoutout to my teammates Nick Turner, Madhu CS, and Palash Agrawal for all of their support!
…
We are always looking for more individuals who share our commitment to building a diverse team and creating an inclusive environment as we continue in our journey in democratizing finance for all. Stay connected with us — join our talent community and check out our open roles!
…
© 2024 Robinhood Markets, Inc.
…
3590886
Related news