
Increasing Efficiency & Confidence with Project Apollo

Increasing Efficiency & Confidence with Project Apollo
What is Project Apollo?
As Robinhood continues to add more microservices, we face new challenges in developing and testing cross-service features. As testing service challenges become more complex, the risk of bugs slipping into production can increase, and complex new features or changes may take longer to develop.
In the past, Robinhood has been able to scale through development in a single shared “dev” environment and manual cross-service testing, primarily because teams were small, and the number of distinct software systems was limited. However, as Robinhood scales, these methods will become less viable. New features will increasingly require communication among many different backend systems, and individual engineers often may not be able to understand the full picture of these interactions.
Because Robinhood is scaling quickly, we see the potential for outgrowing our previous development and testing infrastructure and have decided it is time for an upgrade: Project Apollo. Here’s what we want to accomplish with Robinhood’s next generation testing environment:
- Improved development velocity for all engineers. Frontend engineers relied heavily on the shared “dev” environment to test their UIs against backend services. However, backend engineers also use this environment to test experimental changes, which can destabilize the environment. When something doesn’t work in dev, a frontend engineer has to wait for a fix, which depending on the complexity, can introduce significant delays into the development cycle.
- Improved reliability. Besides enabling engineers to do more manual testing end to end, it also offers an automated integration test platform at scale. Automated integration testing can reduce the risk of broken cross-service interactions, which can in turn lead to production outages. As the number of services grows, integration testing is more and more critical. This also enables QA to test more scenarios in a safe environment.
- A faster onboarding for new engineers. New engineers join Robinhood and are often quickly tasked with testing a small service-to-service interaction they are developing. The process to date has been to set up the interaction in the shared “dev” environment, which involves a cumbersome process of figuring out which pieces of the puzzle already exist, how the environment is configured, and how to introduce a new component. Because of the ever-changing nature of the dev environment, it’s very possible that their setup will be broken which can create a very poor experience for new engineers.
With Project Apollo, Robinhood engineering aims to move faster with increased confidence by:
- Providing a reliable integration testing platform
- Providing personal, isolated, production-like development environments for every employee
- Promoting a cultural shift towards making features testable as they are developed
How does it work?
It is becoming increasingly clear that a single, shared environment is fundamentally unsustainable for both development and testing, for the following reasons:
- Integration tests cannot run in parallel with code changes being made to the system.
- Significant manual effort is required to maintain it; teams are forced to perform oncall duties for their services in the dev environment.
- It’s difficult to track changes and deployments, and when things break, identify which changes caused the problem.
- Data is shared across all users increasing the potential for unintended modifications, and tests that require a clean slate or special setup are essentially impossible to run.
The Apollo solution abandons the idea of a shared environment, and introduces personal, isolated development environments for every employee. The Apollo tools leverage Kubernetes to allow any employee to launch a fresh environment at any time. The configuration for these environments lives entirely within the code for each service, and is tested automatically on every code change. In this way, ownership of dev is completely distributed to the individual services that participate, and dev is treated as an internal product that is constantly tested and released, rather than as a separate system.
The Apollo initiative also solves a few key issues we had identified around integration tests to backend services. Prior solutions were less effective for a few key reasons:
- There was a lack of ownership for the tests; they lived in their own repository separate from the services themselves.
- It was difficult to track which changes caused tests to break; therefore tests were often broken and difficult to fix.
- Running integration tests is difficult on a shared environment because it requires exclusivity; but running locally can consume too much CPU power and memory to be practical.
Apollo requires that each service own and maintain its own integration tests. Integration test code lives alongside application code, and tests are executed on every commit, so engineers know immediately if their changes break the tests. We also leverage Kubernetes to enable engineers to easily run the tests from their laptops, so they don’t have to wait for a remote CI build to know if the tests passed. Test reliability is increased by flakiness mitigation tools built into the framework.
The Apollo initiative also treats data as a first class testing problem by reinforcing that features must be developed to be testable. This means: building mock versions of third parties (such as execution venues), adding additional functions to existing services to allow tests to manipulate and create data, and allowing each test to start with a completely clean state of the data. We are actively working with product teams to ensure their specific data needs are met, and establish best practices for creating test data.
Technical Implementation
Figure 1 to Figure 4 demonstrates how developers interact with Apollo.
it-utils
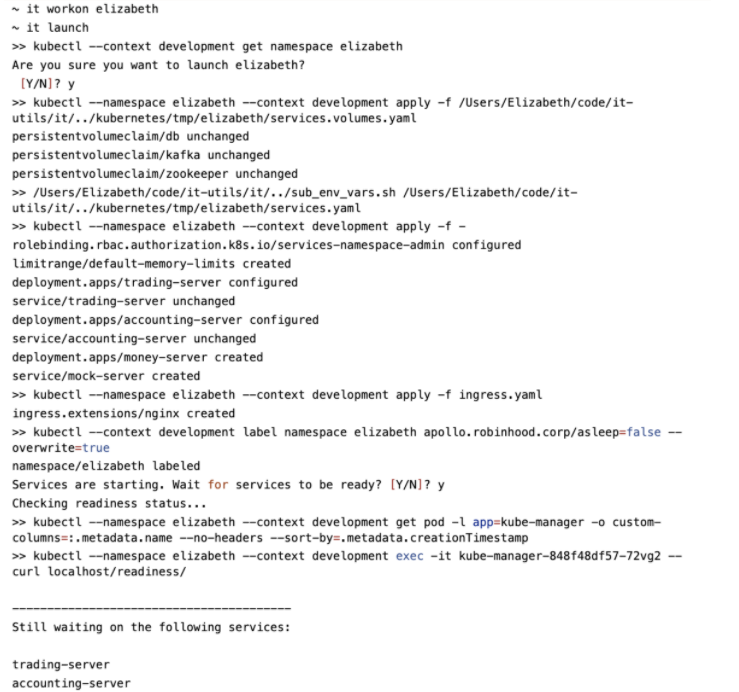
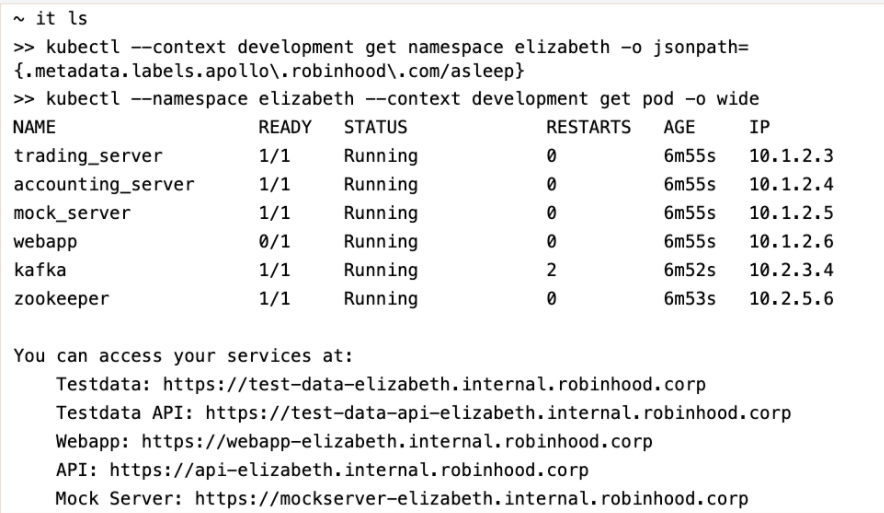
it-utils is a python binary to interact with their personal development environment. The python binary is the thin client that sits on top of Docker and Kubectl (k8s cli). There are a few key commands:
- `it launch` : Launch the personal development environment
- `it recreate`: Recreates the image using local code and Docker file configuration and replaces the running container in the namespace by the created one.
- `it ssh`: Log into the container.
- `it watch`: Sync the local application code into the container in the background.
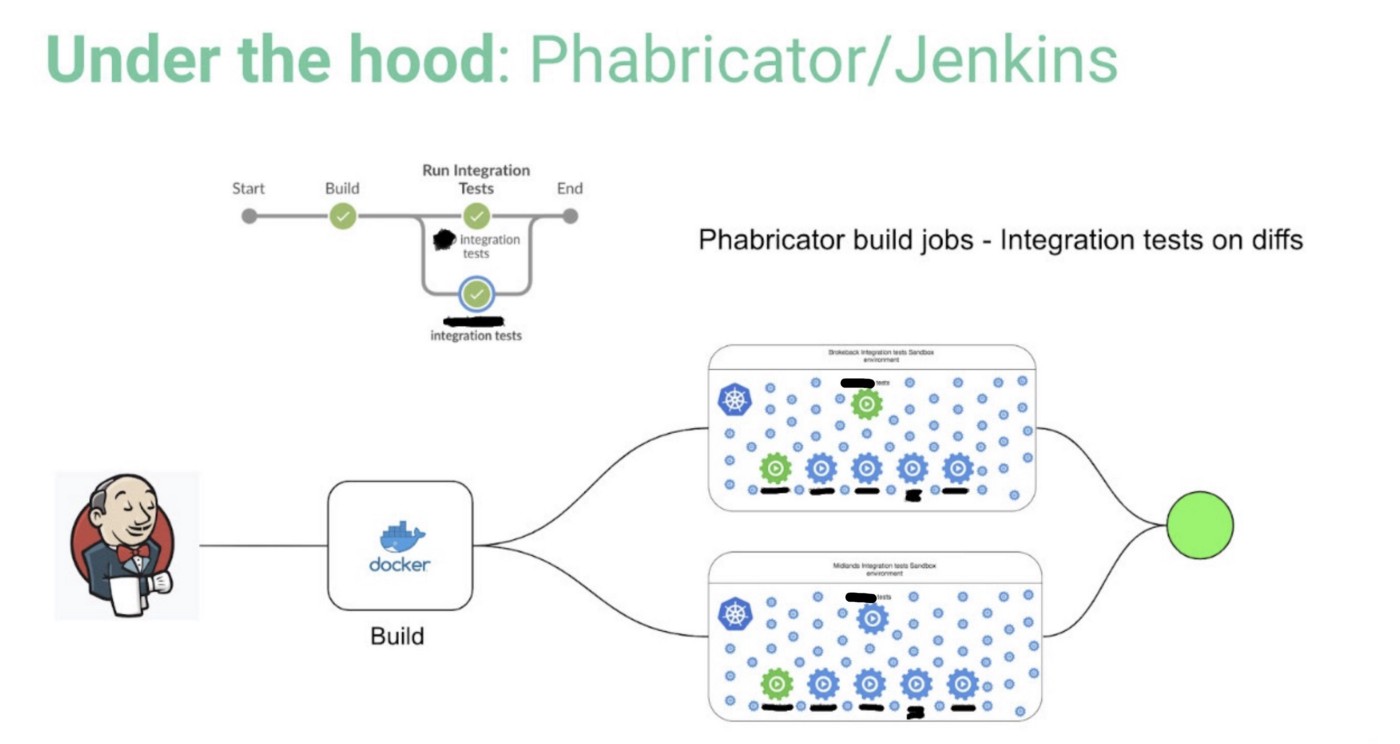
Jenkins pipeline
Jenkins CI jobs are set up to run integration tests on new code change. There are 3 major integration tests:
- Phabricator Jenkins job: Phabricator is linked to integration test Jenkins job on all platforms including Android, iOS, Web, backend, which creates a random test namespace once the diff is created.
- Master Jenkins job: Once the diff is landed, a master Jenkins job is triggered to run the integration tests. If all tests pass, a new image will be published.
it-clients and mocks
The data creation is all done through API calls. it-clients is a wrapper for API calls to create data and wait for created data to populate across services. For example, the instrument flow in it-clients will call Quiver (a service that keeps the source of truth for all instruments) and wait for the created instrument to sync with other services.
Because Robinhood uses multiple repositories, it-clients is a convenient shared library for different services to share the test utils code.
Third party mocks are created as separate image. The code usually lives in the service that directly interacts with the mock. Some third party mocks are stateless while some are stateful and requires external input to control the return result.
Apollo’s impact so far
We’re really excited by the progress we’ve seen since shifting to Apollo.
First, some metrics:
- Today, over 50 services are on Apollo, which is almost all backend services.
- Majority of backend and front-end engineers are using Apollo on a weekly basis.
- More than 350,000 pods/containers per day get created.
We’re also seeing other great productivity improvements:
- The speed of development and collaboration between teams has improved. Backend and frontend engineers can now develop in parallel and demonstrate their work along the way, eliminating the need to wait until “integration day” to test everything together.
- Reliability has improved and we’ve even identified and resolved critical production bugs.
- The virtual environment is also suitable for our QA team to conduct important testing.
But, we know this is not the ultimate solution to improve developer speed and reliability. There are still areas that Apollo could improve and more tools and controls to build. Here are some examples:
- Creating better alignment across teams. Building integration tests and making features testable (especially from the frontend perspective) requires participation from many services and teams. It is like building a social network, which is hard to get started, so we’re working through how we encourage the team to migrate to a new platform.
- Continuing to prioritize and better integrate testing with product, including building testability in the form of mocks and data manipulation endpoints.
- Achieving test stability. As a distributed system owned by multiple teams, we need to continually account for the fact that instability could be caused by an application bug (e.g. race condition of multi-process service), Kubernetes cluster due to large scale of test runs, or Apollo framework (e.g. services startup dependency).
A huge thank you to the core team and partners across Robinhood who have been working on Apollo: Elizabeth Hong (core team), Nathan Ziebart (core team), Mark Rietveld, Colin Reisterer, Shahmeer Navid, Uday Ruddarraju (core team), Baogang Song, Henry Tay, Deen Adzemovic (core team), Zero Cho, Kunal Desai, Vishal Kuo, Adam McCarthy, Mary Pimenova, Jordan Garside, Harry Li (core team), and Chris Boggs, and many other Robinhood teams [1]!
If you’re interested in joining us as we grow Engineering at Robinhood and create solutions like Apollo, take a look at our open roles on the Robinhood careers page.
[1] The list is ordered by starting time of project contribution.


